
Introduction
Since the introduction of the personal computer, interaction of users has become the default mode of developing applications, but as users come to expect more and more features with less and less processing time. If Amazon generated a new recommendation list on each page load, they wouldn’t have gotten very far in the retail space.
Explanation of Terms
That title’s a mouthful, so let’s break down some of the terms and how they relate to each other.
Non-Interactive Processing
Non-Interactive Processing is any type of information processing where the user doesn’t expect immediate feedback for their actions. Typically most things we associate with user applications are interactive processing. When you update your status on Facebook, you expect to be notified of its status. When you click ‘Purchase’ on your Amazon mobile app, you expect to be notified of an issue with your credit card immediately. Non-Interactive processing is anything that is pushed off to be processed later. Your Amazon recommendations are a great example of this.
Directed Acyclic Graphs
A graph is a mathematical structure that has any combination of nodes and edges linking those nodes (seen below)
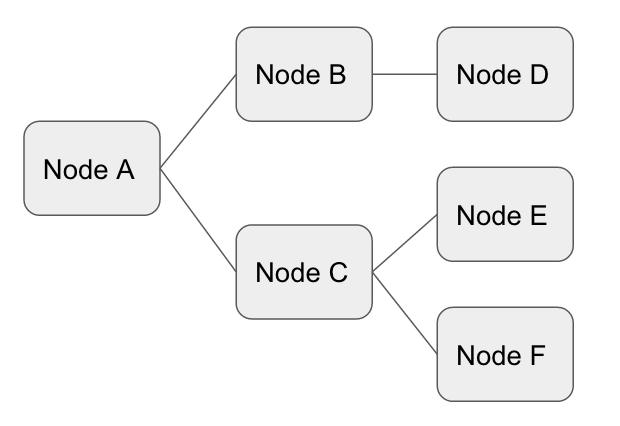
In software engineering, and for the purposes of this blog, we say that nodes represent a collection of statements that the machine will execute and the edges represent a transition from one collection of commands to another.
A directed graph is a graph in which one node has a directional transition from one node to another (see below)
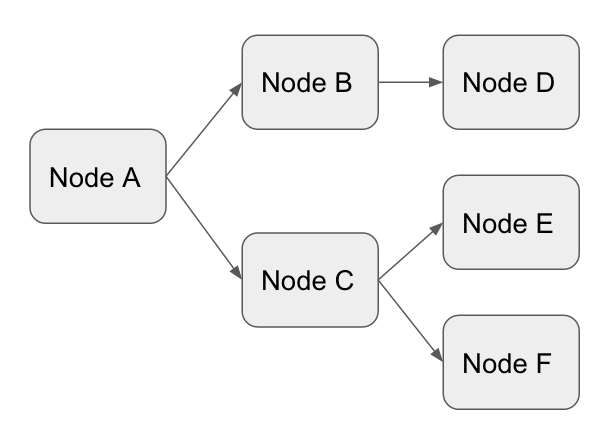
In this example, Node A can transition to Node B and Node B can transicion to D, but Node B can never transition back to Node A. In a standard directed graph, the nodes could be organized so that B points back to A as well, which brings us to the idea of an Directed Acyclic Graph (DAG). An Acyclic Graph requires that no node be able to execute twice. In other words, once a Node has finished running, there should be no way for it to be able to run again. The above graph is acyclic, and below are some examples of graphs that are not acyclic.
In example 1, A->B->A. In example 2, A->B->D->A. In example 3, A->B->D->E->F->A. All of these are examples of graphs where cycles exist (non-acyclic)
Putting it back together
One of the most common ways in which non-interactive programs are structured is using DAGs. Some of this is historical. Unix systems, for example, come with a wide selection of commands that do one small task very well, and the results of these tasks are then forwarded to other tasks. As we’ll see in the rest of this post (as well as future ones), setting up your non-interactive systems using DAGs is just good design as well.
Benefits
Modularization
Each node in the DAG is responsible for one task and one task only. Not only does this help us sort out responsibility in an effective way, but it also means that we can reuse any component in multiple DAGs.
For example, Twitter email you several times a week about tweets in your network and people you should be following. This module can now be reused to email you when you’ve been retweeted.
The argument could be made to export the email function as a library and use the library instead, but we’ll see in later entries about (!!!) and (!!!) that separating them can have very useful, even necessary consequences.
Not Repeating Work
This especially holds true for batching systems, but one monolithic ETL app that processes all your information from start to finish can be very expensive when the system fails. Imagine a batching system that runs for 20 hours, and it fails at hour 19. If it’s one monolithic app, you need to repeat those 19 hours to get to the last hour that failed to run. When you divide the work into self-contained, modularized nodes, you only need to repeat that last hour once the bugs have been fixed.
Stitching Together Languages
Every language does one particular thing very, very well. For example, I’m a big fan of MySQL’s Java library for batch inserts, but Python handles statistical data manipulation sooooo much better. One of my favorite tricks is to do all your statistical processing in Python, flush the data to disk as a CSV, and have Java read them in and batch insert everything. It sounds complicated, but, since you’ve modularized the Python and Java code, stitching them together with a DAG is easier and quicker than using one language to do both things.
Moving Forward
Now that we’ve got the basics covered, we’ll move into two implementations of the DAG, queueing systems and batch processing (forthcoming).
1 comments
2 pings
Hello boy! you wanna see more nudes? Check my videos for link!
https://sexxsy.page.link/2fZQ
[…] « Directed Acyclyic Graphs (DAGs) for Non-Interactive Processing […]
[…] the first and second parts of this series, we discussed what a DAG is and what abstract benefits it can […]