
Introduction
In the first and second parts of this series, we discussed what a DAG is and what abstract benefits it can offer you. In this article, we’ll talk about what benefits it can offer you in a batch processing system. We’ll use customer reviews as our example since retailers will often use these reviews to improve their recommendations for you as well as inform specific storefronts or different parts of their business about reviews and changes in perception.
This post assumes that user is already familiar with the concept of batch processing whether that be bash or a more modern processing system.
Here, we’ll be using an open-source tool, Airbnb’s Airflow, for our examples. If you haven’t checked it out yet, definitely do that. It will schedule all of your processing just like cron jobs, give you the run time stats such as when it was scheduled, its current status, etc, and it will also automatically keep dependent nodes from executing if one fails. It can be found on GitHub at https://github.com/airbnb/airflow
Implementation
The Naive Way
Similar to a queue DAG, it’s tempting to implement batch processes as one monolithic program, though the reasons why this falls down differ slightly from the queue. Typically when dealing with batch systems, a set of operations are run, and the output of these method (an aggregation, for example) is then fed to other methods to compute different values. For example, we need to compute all customers’ star ratings before we can reliably recommend other purchases to them. It’s only at the end of this whole process that the contents of this process are committed to the database.
Batch process can get very expensive very fast in terms of both computation and development time, especially for batch processes that aggregate large swaths of information. These systems can run for hours, so any failure part way through can result in significant lost time in both debugging and processing time. The processing time is self evident, but consider the case of debugging the information. Obviously you have a stack trace, but your devs can sit there for hours in debug mode waiting for a hook to catch even if they’re using test data. If their initial bug fix didn’t work, count on them waiting another couple of hours.
A Better Way
For this example, we’ll consider the case of processing customer reviews on a site like amazon. When a customer submits a review, there are a couple of things we’ll want to do
- Determine a new star ranking for the product
- Alert the vendor about changes
- Determine what recommendations and promotions we should send to the customer
- Determine if the vendor meets our quality standards
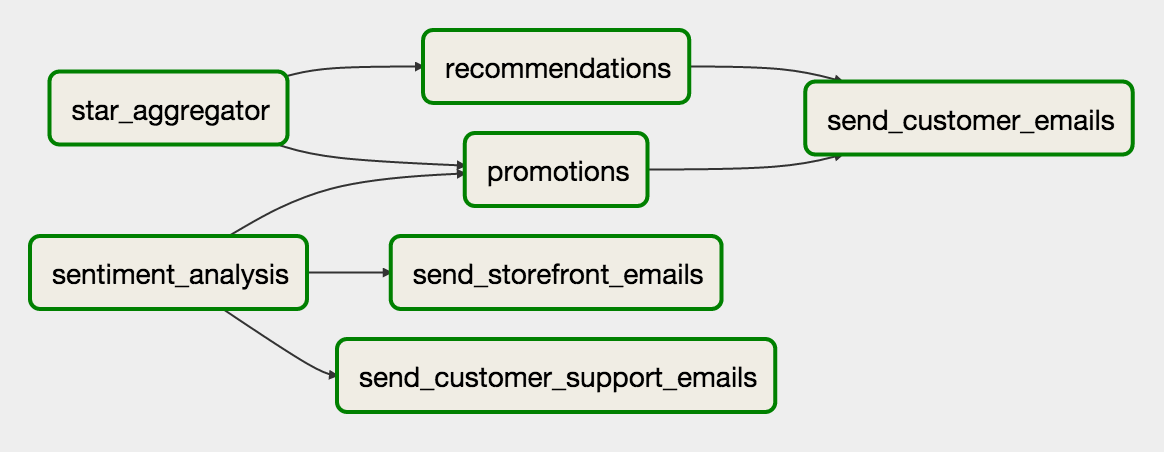
This is a direct screen shot of a workflow from airflow. Similar to the Queue DAG, this flow of control looks a bit more complicated than a standalone monolithic program, so we’ll talk about what each piece does and why it’s designed this way.
To start, each node in the graph represents one distinct task, and each arrow implies a dependence on a previous item. For example, the ‘recommendations’ task is can’t run (is dependent) until the ‘star_aggregator’ task has completed.
Additionally, Each node in the DAG should be responsible for only one type of information or one task, and it should save the information either into a database or to disk in between each step. This differs slightly from the Queue DAG model, which required us to either transform or save information but not both. However, the queue itself acted as a data store in this case. Information posted for the next job was saved to the queue; essentially, we were relying on the queue to save data in between each step. For batch operations, we should do it ourselves.
The largest difference between the flow of control in batch systems vs queueing systems is that batch systems can set a dependency on more than one other task. In the above example, ‘send_customer_emails’ is dependent on both the ‘recommendations’ and ‘promotions’ task. Once both of those finish executing, we know we can execute the ‘send_customer_emails’ task. In a queue, there’s no way a node to determine if previous tasks have finished executing, only that there’s a unit of work available. In a batch system, we can keep track of which units of work have completed successfully, so we can have multiple dependencies in our system.
Benefits
Errors Cause Less Wasted Time
This is far and away the biggest reason why I’ve done things up like this in the past. It’s kind of inevitable. You’ve tested for all the cases currently in your database, but someone enters a control character that you didn’t think about, which causes your whole program to come crashing down around you. DAGs (and AirFlow particularly) help to keep you from losing too much time. When one task fails, all the tasks downstream don’t even bother to execute, so you can deploy a quick patch to your DAG, and only rerun the items that either failed or didn’t run because of a failure upstream. You don’t have to wait for your monolithic app to finish all the previous steps before executing your hot new fix.
Better Success State Handling
When a set of information is committed to the database in a monolithic app, you have no choice but to either say, ‘Everything completed successfully’ so as to not add duplicate data to the database or you have to do complex error handling states to determine if values have been successfully added or not. When using a DAG, each task is modularized so that an error at most points only requires rerunning the current node. The one exception to this is if the task fails midway through saving it to a data store, but any point leading up to that should be easy to fix, run again, and have correct output.
Minimizing Integration Points for Fast Debugging
In a monolithic app data structures can interact in ways that can lead to silent failures. An example of this may be that a method modifies 1,000 entries in your set early on in execution, no one realized what kind of issues this may lead to later on in execution, and now you have wrong data but don’t know how it got in there. This can be a nightmare to debug. In a DAG, we know the expected input, so diagnosing what led to this problem (such as an errant SQL call) becomes a routine case of opening your SQL client and trying out queries that will lead to the right answer.
Additionally, there are only so many places where each process can go wrong. The data loading, the transformation, and the saving. Right from the start, you know a task failed because of one of those things; not that something happened at the start of the program that was modified sixteen steps before the error was thrown in some nested function written by Steve at the end of the office. Walking the error back to the beginning of this particular process is a much, much shorter trip than going back thousands of lines of code in a monolithic ETL.
Better memory management
This is particularly true in languages that rely on garbage collection. Every C developer knows exactly where and when we should reclaim memory, but most of us aren’t C developers. In a monolithic app, a giant data structure that’s no longer used needs to be dereferenced in order for it to be eligible for garbage collection, so we’ve got to determine where and when every data structure is used and when it’s not being used anymore. Using a DAG model, the starting and stopping of tasks will implicitly handle this garbage collection for us. A massive set opened up for the first process in a long chain releases its memory as part of that task completing.
Cheap Multiprocess Support
This is especially true with Airflow’s simultaneous execution of many tasks. Let’s say we have an eight core EC2 instance. In monolithic apps, we’d have to pay very close attention to threading in our large scale processes; otherwise, we’re only using one of those cores. However, Airflow’s concurrency model will automatically run each non dependent process at the same time up to a certain limit (we don’t want our processors thrashing now). It will then run all the dependent processes concurrently as well. In the example above, ‘star_aggregator’ and ‘sentiment_analysis’ will run at the same time. After they’ve been completed successfully, ‘recommendations’, ‘promotions’, ‘send_storefront_emails’, and ‘send_customer_support_emails’ will be run simultaneously next. This has the net effect of significantly speeding up your execution time without putting in much more work.
Conclusion
For non-realtime processing, using a DAG model and a tool like Airbnb’s Airflow can significantly speed up your development time and make your code maintainable over the long haul. It’s can be slightly more work to define integration points and set up the dependencies, but those drawbacks are a one time investment for a system that will run better and smoother over the long haul.
Recent Comments