
Introduction
You’re trying to decide which products are most important to your customers, or maybe the marketing team is interested in how many widgets have been sold to each industry, or you’re trying to list which five pages in your project are most viewed. To add another wrinkle, the key stakeholders in your project want to be able to interact with the information themselves, and you’d happy they won’t keep coming to you every time they need a data pull.
The key question still remains, how do you aggregate all this information over millions of records in a reasonable amount of time? The the previous part of this tutorial, we covered how to use sets for duplicate information, and there is a way to make that work here. However, we’d prefer something a little cleaner.
In this tutorial, we’ll talk about using maps to efficiently handle aggregations across multiple tables, so you’re left with one insert per unit instead of tons of updates to records in the database. Or, worse still, millions of queries
Getting Started
What are Maps?
The quick answer is that maps are data structures that contain a set of key value pairs. One key maps to exactly one value in the dataset. For example, in the following example:
Key1=Value1
Key2=Value2
Key3=Value3
Key1=Value4
The final value of the data set will be (Key1=Value4, Key2=Value2, Key3=Value3). These are similar to associative arrays found in JavaScript and in PHP.
The reason why we’re using hash maps here are for their insert / index speed. In a typical list, accessing an individual element is time O(N), adding to it is O(1). What we’d find then is that querying a list for its values across all keys would result in a runtime of O(N2), whereas maps would be a runtime of O(N) – iterating over all keys. For small sets, this difference is pretty negligible, but it quickly becomes an issue when we start getting into the millions of records. Suddenly, you need quadrillions of operations for lists instead of millions for maps.
Example database
For this example, Discogs.com is nice enough to give away their entire data set once of month full of of musicians, albums, labels, etc, so we’ll be using a much, much simplified version of their amazing database. For this example, we’re interested in collecting aggregate information about a particular artist to determine the breadth of their music industry exposure.
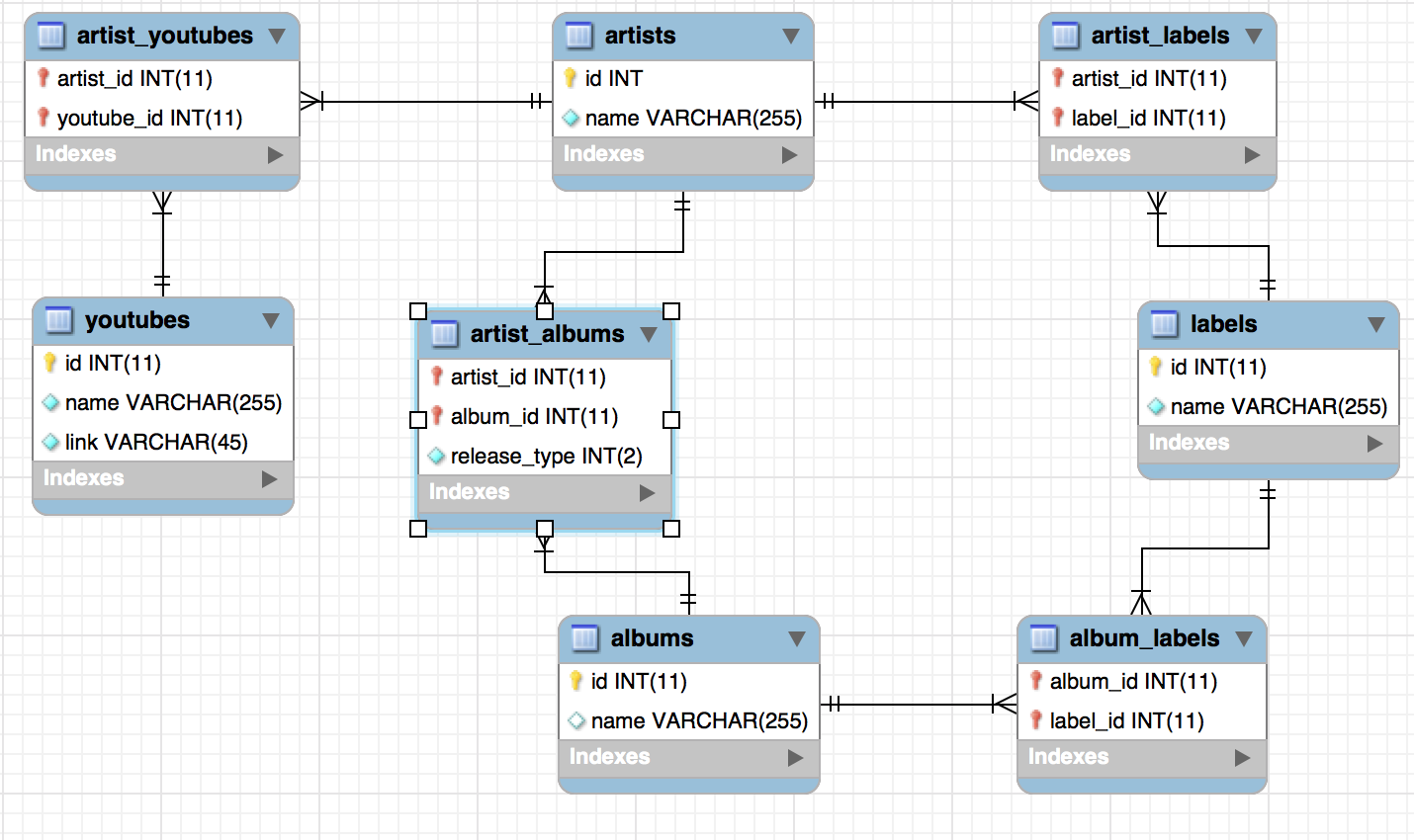
Above is a MySQL workbench screenshot describing how all this information fits together in our database. This does violate 2NF, but it’s useful to see the relationship between all the elements in the dataset. Artists (middle top) contains a globally unique id as well as the artists’ names. We also have labels (center right), albums, (middle bottom) and youtube videos (center left). These are connected through their various join tables – artist_albums, artist_labels, album_labels, and artist_youtubes. On important note is that artist_albums also contains a field, release_type, which determines if this was their release, if they guess stared on the album, if they produced it, etc.
Implementation
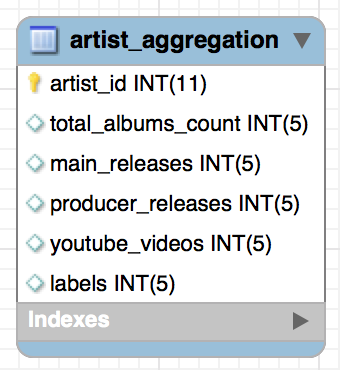
We’ll be populating a table that contains the following entries:
- total_albums_count – the number of albums the artist is associated with
- main_releases – the number of albums this artist has released
- appeared_on_releases – the number of albums this artist had a contributing vocal role on (backup singer, guest rapper, etc.)
- producer_releases – the number of albums this artist was a producer on
- youtubue_videos – the number of youtube videos we found for this artist
- labels – the number of labels this artist has appeared on
So the first thing we’ll do is create a Java class to hold this information
public class ArtistAggregation {
private int artistId;
private int mainReleases;
private int appearedOnReleases;
private int producerReleases;
private int youtubeVideos;
private int labels;
public int getArtistId() {
return artistId;
}
public void setArtistId(int artistId) {
this.artistId = artistId;
}
public int getMainReleases() {
return mainReleases;
}
public void setMainReleases(int mainReleases) {
this.mainReleases = mainReleases;
}
public int getAppearedOnReleases() {
return appearedOnReleases;
}
public void setAppearedOnReleases(int appearedOnReleases) {
this.appearedOnReleases = appearedOnReleases;
}
public int getProducerReleases() {
return producerReleases;
}
public void setProducerReleases(int producerReleases) {
this.producerReleases = producerReleases;
}
public int getYoutubeVideos() {
return youtubeVideos;
}
public void setYoutubeVideos(int youtubeVideos) {
this.youtubeVideos = youtubeVideos;
}
public int getLabels() {
return labels;
}
public void setLabels(int labels) {
this.labels = labels;
}
}
Putting it All Together
Now, let’s get into the meat of the article, how to use maps. What we’re going to do here is create a new map for every type of information and then combine into a composite data structure before inserting into the database. For this example, each map is going to be populated from one method that takes a query string with a specific structure as an argument. We’ll then iterate over the total set of all artist ids and check for the required information in the map to construct our final database object. If this sounds a little confusing, check out the code block below, and it’ll become a lot clearer.
We could do all of this on the fly using a visitor pattern for all of the methods that populate the map, but I generally shy away from that pattern. Over the life of the program, it doesn’t save us that much time or space, and it can be confusing to maintain for very large aggregation tables (think 50+ elements).
The following is exactly how this is all going to be implemented in Java:
// return a map with a key of the artist id and a value of whatever we're counting.
// The user must specify a query of the type "select artist.id, count(*) c from..."
private Map<Integer, Integer> fetchIdCount(Connection conn, String query) {
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
Statement statement = conn.createStatement();
ResultSet set = statement.executeQuery(query);
while (set.next()) {
map.put(set.getInt("id"), set.getInt("c"));
}
set.close();
statement.close();
return retval;
}
// Get all artist ids. We'll use this to iterate over later
private Set<Integer> fetchAllArtistIds(Connection conn) {
Set<Integer> set = new HashSet<Integer>();
Statement statement = conn.createStatement();
ResultSet set = conn.createStatement("select id from artists");
while (set.next()) {
set.add(set.getInt("id"));
}
set.close();
statement.close();
return retval;
}
public Set<ArtistAggregation> aggregate(Connection conn) {
Set<ArtistAggregation> retval = new HashSet<ArtistAggregation>();
Set<Integer> allIds = fetchAllArtistIds(conn);
Map<Integer, Integer> youtubes = fetchIdCount("select a.id, count(*) c from artists a, artist_youtubes ay where a.id=ay.artist_id group by a.id");
//Assume the album_type code for producer is '5'
Map<Integer, Integer> produced = fetchIdCount("select a.id, count(*) c from artists a, artist_albums aa where a.id=aa.artist_id and aa.release_type=5 group by a.id");
//Assume the album_type code for appeared on is '2'
Map<Integer, Integer> appearedOn = fetchIdCount("select a.id, count(*) c from artists a, artist_albums aa where a.id=aa.artist_id and aa.release_type=2 group by a.id");
//Assume the album_type code for main release is '0'
Map<Integer, Integer> mainRelease = fetchIdCount("select a.id, count(*) c from artists a, artist_albums aa where a.id=aa.artist_id and aa.release_type=0 group by a.id");
Map<Integer, Integer> labels = fetchIdCount("select a.id, count(*) c from artists a, artist_labels al where a.id=al.artist_id group by a.id");
for (Integer artistId : allIds) {
ArtistAggregation aa = new ArtistAggregation(artistId);
if (youtubes.contains(artistId)) {
aa.setYoutubeVideos(youtubes.get(artistId));
}
if (produced.contains(artistId)) {
aa.setProducerReleases(produced.get(artistId));
}
if (appearedOn.contains(artistId)) {
aa.setAppearedOnReleases(appearedOn.get(artistId));
}
if (mainRelease.contains(artistId)) {
aa.setMainReleases(mainRelease.get(artistId));
}
if (labels.contains(artistId)) {
aa.setLabels(labels.get(artistId));
}
}
return retval;
}As you can see above, we’re first grabbing all the known artist ids and using that as a basis to determine if that artist does have entries into the various aggregation hash maps.
Conclusion
We’ve walked through why exactly you should use hash maps to store various pieces of aggregate information in order to construct the final object, and we’ve looked at how that type of system would work.
We can see from the above examples that this approach is simple, clean, and effective. Instead of querying the database N times (where N is the number of artists), we’re querying the database only one time for each type of aggregation, which results in execution speeds orders of magnitude quicker than the alternative!
Recent Comments