
Introduction
In the first part of this series, we discussed what a DAG is and what abstract benefits it can offer you. In this article, we’ll talk about its specific implementation in a queuing system. For this article, I’ll use customer reviews as an example; they’re relatively straightforward, but you’d be surprised at the steps that can occur when you rate your dog food five stars because Fluffy loved it.
This post assumes that the user is already familiar with Queues such as RabbitMQ or Kafka as well as worker threads that process these requests.
How to Implement a DAG
The Naive Way
It’s tempting to implement each worker as a one step process. You post a customer review to the queue, and a worker pulls it off, saves it to the database, sends off emails to the merchant, adds it to the star rating aggregation and then quits. I’ll explain why this is poor practice.
At what point do we define a success condition throughout this process? Do we say ‘mission accomplished’ only when the worker has finished all its tasks? Suppose it fails when it’s processing the aggregation. Now we have to rerun the entire worker process, which results in two entries in the database, two emails sent, but only one aggregate added to the database. We almost have to say ‘mission accomplished’ once its been added to the database to avoid duplication and mark it as ‘completed’ only when the worker has finished, but now we’re adding unnecessary state to the database and extra steps to the worker, steps that are a nightmare from a maintainability standpoint.
A Better Way
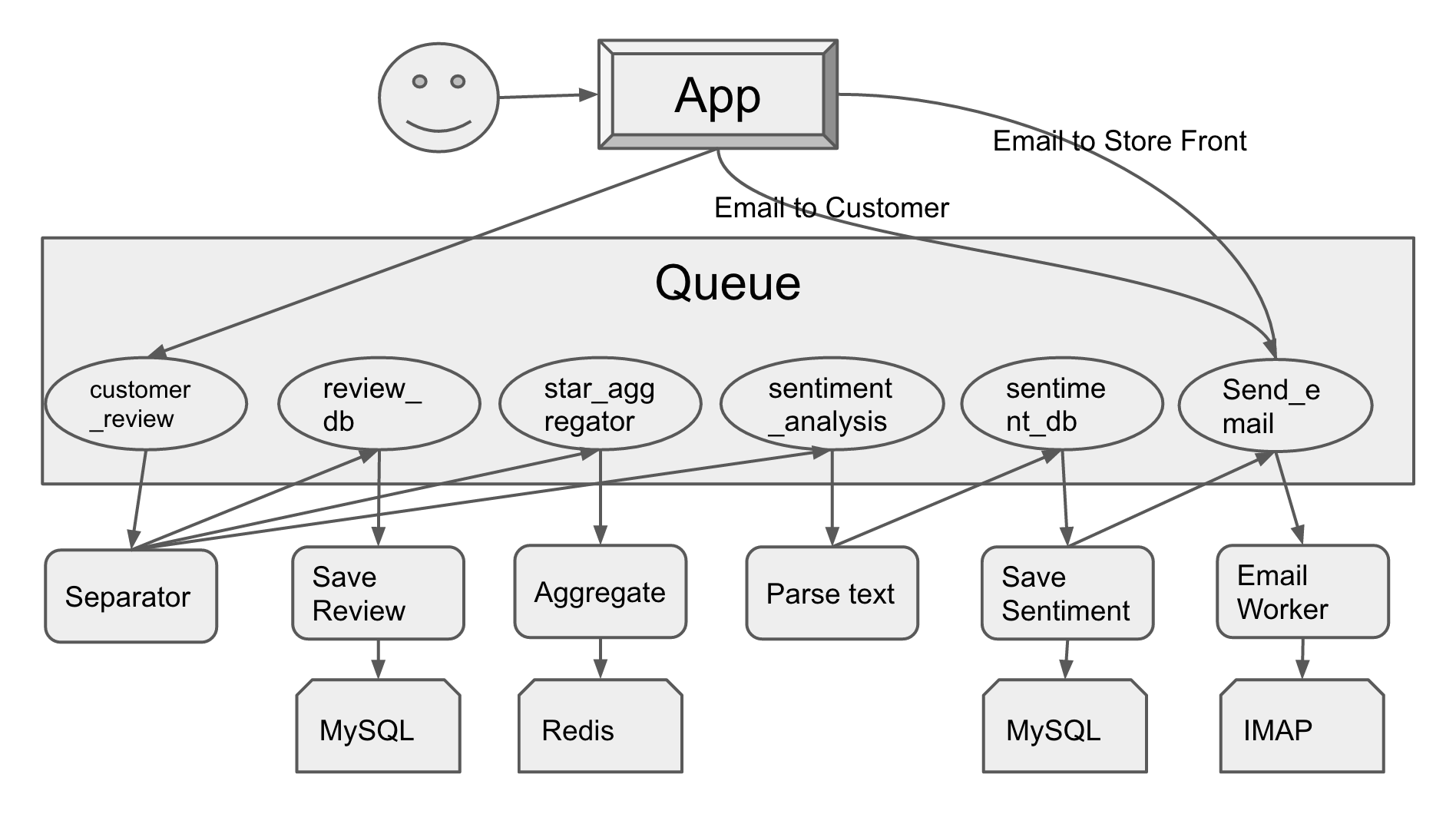
I know this looks complicated, so bear with me for a moment, and I’ll explain what this is doing and why.
Each node in the DAG should either transform information or save it but not both. Why? There are a couple key reasons; some of which were covered in the first entry in the series, but we’ll look at those again as well as what’s specific to just the queue DAG.
Modularization
This is the most self-evident of the three big reasons. It’s easy to see in this case that the email node is being used by three wholly separate processes. The mail protocol isn’t likely to change from email to email, so as long as the information placed in the queue follows the same pattern, it’s trivial to reuse the same code. Additionally, it’s easy to imagine how a ‘storefront review’ form would map directly from the app to the sentiment analysis queue instead of the ‘customer_review’ queue.
Error Handling
This is easily the biggest of the top three. Since each node is only responsible for one task, there’s no work that gets redone as a result of a failure. If the sentiment analysis fails because of a flaw in the programming, we don’t need to care if it’s been saved successfully or if the star aggregator worked. We know that we can just try again when the code’s been fixed.
What makes this possible is that a queue worker only has to tell the queue that it successfully processed the message _after_ it’s finished. If there’s an error in the logic that prevents the successful completion of the task, it stays on the queue, and the worker tries again. Similarly, if there’s a network partition that keeps ‘Save Review’ from accessing the MySQL database, the message can go back on the queue to try again.
At the end of this article, I’ll list out the things you’ll want to save as error messages.
Scalability
This is the least thought about reason of the big three, but it’s also what gives this model a lot of power. The sentiment analysis here is the most CPU bound of all of the processes. Since any machine that has access can read from the queue, the workers for sentiment analysis can be placed on an Amazon C4XL for maximum power. The others are IO bound, so throw them on a micro instance, and you’ll be fine (don’t actually do that, but a small server would be totally fine).
Additionally, you can only process one queue at set intervals to save time and money. If you look at star ratings every hour but only review sentiment analysis first thing in the morning, then why not rent a machine for an hour each night to process the sentiment analysis queue? Or if you notice that no one does reviews at 2AM, start a cron job to only start sentiment analysis at 2AM on your smaller machine.
It’s Only Slightly More Work
Seriously. You were going to implement all the logic of the workers anyway, so why not take advantage of better architecture?
Error Messages
Since good error messages are the life blood of maintainability, this gets its own section.
In addition to placing information the next worker will need, the worker should also pass along these values to all subsequent workers; think of this as the queue stack trace. Here are the things you’ll want to save:
- Worker name – Which worker threw the error (i.e. ‘Save Review’ above)
- Time request was issued – What time did this worker first get the message?
- Time request was finished – What time did this worker fail?
- Processing time – How long was spent on this message? Did it churn for an hour or fail right away?
- Status – Success or failure?
- Server Name – IP Address or the name of the server this worker was running on
- Message (maybe stack trace on error) – If you get a stack trace, put it in the error; this should go without saying :)
- Queue Name – What queue did this worker pop off of
- Queue Message Id – If operations are idempotent, list the message
Further reading:
If you want more theory and some more examples, one of the easiest to read is Queue-based System Architecture: Build Scalable, Fault-tolerant Distributed Systems. Added bonus: it’s free with Kindle Unlimited!
Recent Comments