
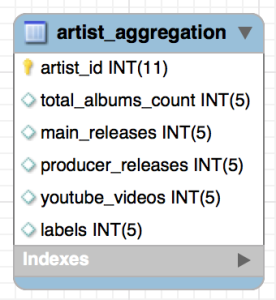
Introduction You’re trying to decide which products are most important to your customers, or maybe the marketing team is interested in how many widgets have been sold to each industry, or you’re trying to list which five pages in your project are most viewed. To add another wrinkle, the key stakeholders in your project want to …
Recent Comments